| *** tpb <[email protected]> has joined #yosys | 00:00 | |
| *** vidbina <[email protected]> has quit IRC (Ping timeout: 268 seconds) | 00:41 | |
| *** citypw <citypw!~citypw@gateway/tor-sasl/citypw> has joined #yosys | 01:28 | |
| *** bl0x_ <bl0x_!~bastii@p200300d7a7172200fba0d562efa7c9cd.dip0.t-ipconnect.de> has quit IRC (Ping timeout: 240 seconds) | 02:22 | |
| *** bl0x_ <bl0x_!~bastii@p200300d7a710cc00d7429a35fc1fea6a.dip0.t-ipconnect.de> has joined #yosys | 02:24 | |
| *** ec <ec!~ec@gateway/tor-sasl/ec> has quit IRC (Ping timeout: 276 seconds) | 02:51 | |
| *** tlwoerner <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 05:46 | |
| *** tlwoerner <[email protected]> has joined #yosys | 05:52 | |
| *** tlwoerner <[email protected]> has quit IRC (Ping timeout: 268 seconds) | 06:04 | |
| *** tlwoerner <[email protected]> has joined #yosys | 06:28 | |
| *** FabM <FabM!~FabM@2a03:d604:103:600:87a3:5c19:7dbe:f486> has joined #yosys | 06:47 | |
| ikskuh | hm, i figured out one hot path without reading the whole source code *grin* | 07:19 |
|---|---|---|
| ikskuh | you shall not modulo arbitrary numbers | 07:19 |
| ikskuh | in synthesis | 07:19 |
| *** vidbina <[email protected]> has joined #yosys | 08:34 | |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has joined #yosys | 09:29 | |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has quit IRC (Quit: Leaving) | 10:17 | |
| lofty | ikskuh: oh yeah, that's really something to avoid | 10:51 |
| ikskuh | yeah | 10:51 |
| lofty | It might be feasible to do sequentially | 10:51 |
| ikskuh | still impressed that i can run 16 mio divs per second | 10:51 |
| lofty | But, definitely not combinationally | 10:52 |
| ikskuh | when i removed it, the synth/pnr jumped to 112 mhz | 10:53 |
| ikskuh | which is already way better | 10:53 |
| ikskuh | but now i need to compile the nextpnr gui so i can figure out where the hotpath actually is | 10:53 |
| ikskuh | because i feel like it should be faster | 10:53 |
| ikskuh | my goal is stable 160 MHz CPU clock with at least 20 MHz margin | 10:54 |
| tnt | is that on ecp5 ? | 10:59 |
| ikskuh | yeah | 11:00 |
| ikskuh | current design without CPU synthesizes to roughly 202 MHz | 11:00 |
| *** Lord_Nightmare <Lord_Nightmare!Lord_Night@user/lord-nightmare/x-3657113> has quit IRC (Ping timeout: 240 seconds) | 11:07 | |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has joined #yosys | 11:57 | |
| ikskuh | the gui is really slow /o\ | 12:14 |
| ikskuh | are there requirements for the visualization? i might be able to improve the rendering a lot | 12:14 |
| ikskuh | is there a way to show the critical paths? | 12:24 |
| ikskuh | or reverse net/cell names back to their verilog lines? | 12:24 |
| tnt | try to guess based on the name of the nets ... | 12:26 |
| ikskuh | from to is both "posedge $glbnet$clk" | 12:28 |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has quit IRC (Quit: Leaving) | 12:28 | |
| *** cr1901_ <cr1901_!~cr1901@2601:8d:8600:911:9d70:8f88:7606:6eed> has joined #yosys | 12:40 | |
| *** trabucay1e <[email protected]> has joined #yosys | 12:42 | |
| *** gatecat_ <[email protected]> has joined #yosys | 12:42 | |
| *** dnm_ <[email protected]> has joined #yosys | 12:42 | |
| *** Moe_Icenowy <Moe_Icenowy!~MoeIcenow@2604:a880:2:d1::1d1:f001> has joined #yosys | 12:42 | |
| *** unkraut_ <[email protected]> has joined #yosys | 12:44 | |
| *** gruetze_ <gruetze_!~quassel@wireguard/tunneler/gruetzkopf> has joined #yosys | 12:44 | |
| *** rektide_ <[email protected]> has joined #yosys | 12:45 | |
| *** jix__ <jix__!~jix@user/jix> has joined #yosys | 12:45 | |
| *** Kamilion|ZNC <Kamilion|[email protected]> has joined #yosys | 12:45 | |
| *** _whitelogger <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** Sarayan <Sarayan!~galibert@2a01:e0a:1d7:77e0:beae:c5ff:fee3:518f> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** unkraut <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** jix_ <jix_!~jix@user/jix> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** rektide <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** gatecat <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** dnm <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** cr1901 <cr1901!~cr1901@2601:8d:8600:911:51a1:26ce:1709:19d8> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** Max-P <Max-P!thelounge@thelounge/maintainer/Max-P> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** gruetzkopf <gruetzkopf!~quassel@wireguard/tunneler/gruetzkopf> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** MoeIcenowy <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** trabucayre <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** tux3 <tux3!~tux3@user/tux3> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** Kamilion <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** oldtopman <[email protected]> has quit IRC (Ping timeout: 240 seconds) | 12:46 | |
| *** gatecat_ is now known as gatecat | 12:46 | |
| *** _whitelogger <[email protected]> has joined #yosys | 12:46 | |
| *** dnm_ is now known as dnm | 12:46 | |
| *** oldtopman <[email protected]> has joined #yosys | 12:46 | |
| *** tux3 <[email protected]> has joined #yosys | 12:46 | |
| *** Kamilion|ZNC is now known as Kamilion | 12:47 | |
| *** rektide_ <[email protected]> has quit IRC (Ping timeout: 256 seconds) | 12:50 | |
| *** rektide <[email protected]> has joined #yosys | 12:51 | |
| *** gruetze_ is now known as gruetzkopf | 13:00 | |
| *** trabucay1e is now known as trabucayre | 13:03 | |
| *** Sarayan <Sarayan!~galibert@2a01:e0a:1d7:77e0:beae:c5ff:fee3:518f> has joined #yosys | 13:05 | |
| ikskuh | https://bpa.st/RW3Q | 13:21 |
| tpb | Title: View paste RW3Q (at bpa.st) | 13:21 |
| ikskuh | could someone take a quick peek at this? It's a human readable display of the critical paths | 13:21 |
| ikskuh | every line with a "!" is where the delay is more than the budget, and the cells in the path are displayed afterwards | 13:22 |
| ikskuh | to me it looks like the "cpu halted" is delaying everything? | 13:22 |
| tnt | well kind of hard to say without seeing the sources ... | 13:26 |
| ikskuh | oh, sure | 13:27 |
| ikskuh | https://git.random-projects.net/ashet/mini/src/branch/master/src | 13:27 |
| tpb | Title: ashet/mini - mini - Random Projects: Code for the masses (at git.random-projects.net) | 13:27 |
| ikskuh | spu.v is the problematic file | 13:28 |
| ikskuh | if i remove the instance of the spu_core module, i'm at ~200 MHz | 13:28 |
| *** cr1901_ is now known as cr1901 | 13:48 | |
| *** Lord_Nightmare <Lord_Nightmare!Lord_Night@user/lord-nightmare/x-3657113> has joined #yosys | 14:26 | |
| *** ec <ec!~ec@gateway/tor-sasl/ec> has joined #yosys | 15:29 | |
| *** citypw <citypw!~citypw@gateway/tor-sasl/citypw> has quit IRC (Ping timeout: 276 seconds) | 15:35 | |
| *** cr1901 <cr1901!~cr1901@2601:8d:8600:911:9d70:8f88:7606:6eed> has quit IRC (Ping timeout: 240 seconds) | 15:41 | |
| *** Moe_Icenowy is now known as MoeIcenowy | 15:41 | |
| lofty | ikskuh: this state machine is pretty big | 16:09 |
| lofty | Oh, is this the entire CPU as a state machine? | 16:10 |
| ikskuh | yes | 16:33 |
| ikskuh | "smol" cpu | 16:33 |
| ikskuh | well, it actually is | 16:34 |
| ikskuh | 32 instructions and only some transitions before/after | 16:34 |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has joined #yosys | 16:45 | |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has quit IRC (Client Quit) | 16:46 | |
| lofty | ikskuh: well, CPUs as state machines tend not to go so well | 16:49 |
| lofty | There's a lot of things that Yosys has to merge together when it's probably not necessary | 16:49 |
| *** cr1901 <cr1901!~cr1901@2601:8d:8600:911:c11c:2a92:dcdc:271a> has joined #yosys | 16:52 | |
| lofty | For example the ALU carry things | 16:52 |
| *** gsmecher <[email protected]> has joined #yosys | 16:57 | |
| *** ec <ec!~ec@gateway/tor-sasl/ec> has quit IRC (Ping timeout: 276 seconds) | 17:18 | |
| *** ec <ec!~ec@gateway/tor-sasl/ec> has joined #yosys | 17:19 | |
| *** vidbina <[email protected]> has quit IRC (Ping timeout: 268 seconds) | 17:29 | |
| *** peepsalot <peepsalot!~peepsalot@openscad/peepsalot> has quit IRC (Quit: Connection reset by peep) | 17:38 | |
| *** peepsalot <peepsalot!~peepsalot@openscad/peepsalot> has joined #yosys | 17:40 | |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has joined #yosys | 18:24 | |
| *** sagar_acharya <sagar_acharya!~sagar_ach@2405:201:f:1db9:4a96:8154:92bb:7691> has quit IRC (Quit: Leaving) | 18:38 | |
| ikskuh | lofty: how do i do the CPU then instead? | 18:42 |
| ikskuh | i only know the state machine way | 18:43 |
| lofty | ikskuh: a 3-stage pipeline should be doable | 18:43 |
| ikskuh | hm? | 18:43 |
| lofty | pipelined CPU. | 18:43 |
| ikskuh | doesn't work | 18:43 |
| ikskuh | instructions are 100% dependent on each other | 18:44 |
| lofty | do you think they weren't on older RISC CPUs? | 18:44 |
| lambda | does your CPU not execute instructions in order? | 18:45 |
| ikskuh | lofty, so how does it work then? | 18:45 |
| ikskuh | lambda: i have a stack machine | 18:45 |
| ikskuh | that means op 1 has to be 100% completed before op 2 can fetch data | 18:45 |
| lofty | *or* that op 1 can feed its data into op 2 | 18:45 |
| ikskuh | right, but the memory write still has to happen | 18:46 |
| lofty | And it will | 18:46 |
| ikskuh | but then i don't understand what you mean | 18:46 |
| * ikskuh is still very much an FPGA noob | 18:46 | |
| *** truc is now known as bjonnh | 18:47 | |
| lofty | Imagine, fetch/execute/writeback | 18:47 |
| ikskuh | yeah, i have done that as a state machine right now | 18:47 |
| lambda | ikskuh: I think for the vast majority of unstructions you don't need to fully execute them in order to know that the next instruction will be at pc+1 | 18:47 |
| lambda | so you can already fetch the next instruction while the current one is being executed | 18:47 |
| ikskuh | lambda: i can't, i'm already at 100% memory pressure | 18:48 |
| lofty | I think on a 3-stage pipeline you can resolve the next PC immediately though, right? | 18:48 |
| ikskuh | kinda. | 18:48 |
| lofty | Either a) split instruction and data buses | 18:48 |
| lofty | or b) caches | 18:48 |
| lofty | Which I suppose is a way of achieving a | 18:49 |
| ikskuh | okay, so if i split them and have a instruction cache | 18:49 |
| Sarayan | if it's a stack machine it should already be split shouldn't it? | 18:49 |
| ikskuh | it isn't, it's a von neumann | 18:49 |
| ikskuh | but i still don't understand what you mean with pipeline exactly | 18:49 |
| ikskuh | do i chain stuff together as fifos? | 18:50 |
| ikskuh | *as=>with | 18:50 |
| lofty | No | 18:50 |
| lofty | Just flops | 18:50 |
| ikskuh | hm, okay | 18:50 |
| lofty | okay, let's temporarily put aside the stack machine-ness to look from an ivory tower | 18:50 |
| lofty | You need an ALU - this ALU can do things like shift, add, subtract, etc | 18:51 |
| ikskuh | right | 18:51 |
| lofty | Then you need something to program this ALU to perform an operation | 18:51 |
| lofty | This is your fetch stage | 18:51 |
| ikskuh | is memory read/write performed by alu? | 18:51 |
| Sarayan | no | 18:51 |
| Sarayan | memory access is another logical block | 18:52 |
| ikskuh | okay | 18:52 |
| lofty | You're turning the 3 stage pipeline into a 4-stage pipeline, Sarayan :P | 18:52 |
| Sarayan | alu doesn't care where what comes in comes from, out goes | 18:52 |
| lofty | But maybe 4 stages is easy to explain | 18:52 |
| Sarayan | lofty: then I fold it back, you'll see ;-) | 18:52 |
| ikskuh | okay | 18:53 |
| ikskuh | so i have a thing that fetches the instruction itself | 18:53 |
| ikskuh | which stage/unit fetches the instruction inputs? | 18:53 |
| Sarayan | the #1 trick for a fast stack machine being not to have a real stack in the first place, but independant registers for the top and filling/spilling as needed | 18:53 |
| ikskuh | Sarayan: that's an optimization for future days | 18:54 |
| lofty | unfortunately it isn't. | 18:54 |
| ikskuh | which i have planned already, but i don't wanna do now for simplicities sake | 18:54 |
| lofty | "where do your instruction inputs come from" - from the register file | 18:54 |
| lofty | not from memory | 18:54 |
| lofty | You're at 100% memory utilisation, this is why :P | 18:54 |
| ikskuh | well | 18:55 |
| ikskuh | that is all not a problem atm | 18:55 |
| ikskuh | i know that these are architectural/high level design problems | 18:55 |
| ikskuh | but right now i can live with raw uncached memory access | 18:55 |
| lofty | You came to the channel asking for help with this, did you not? | 18:55 |
| lofty | "why is my CPU slow" because at a high level, it is a state machine | 18:56 |
| lofty | And state machines do not fit FPGAs well because all the logic is happening at once | 18:56 |
| ikskuh | yes, exactly. but i don't see how a "register file" (which i don't know what it is) can help | 18:56 |
| lofty | This is why multiplication, division and modulo are slow | 18:56 |
| Sarayan | well, at higher level your cpu is slow because it does way too many memory accesses and memory accesses are slow | 18:56 |
| ikskuh | ↑ i know this part | 18:56 |
| lofty | If you put the top of the stack in a small memory of its own | 18:56 |
| lofty | a lot of the operations will use this | 18:57 |
| lofty | Maybe even the top N of the stack | 18:57 |
| lofty | And then you can avoid memory operations | 18:57 |
| ikskuh | yes, but this will make the *implementation* itself slower | 18:57 |
| lofty | And you can speed your CPU up by *already having the data* | 18:57 |
| ikskuh | as i need more combinatoric logic | 18:57 |
| lofty | No, you need *less* | 18:57 |
| ikskuh | huh? | 18:58 |
| Sarayan | the amount is not what sets the speed, it's the depth | 18:58 |
| lofty | You can already load data from the stack, can you not? | 18:58 |
| ikskuh | Sarayan: yes, exactly | 18:58 |
| ikskuh | that's why i was thinking it's slower as i need more decisions | 18:58 |
| Sarayan | so more logic is not necessarily slower if it's more parallel logic | 18:58 |
| lofty | So, if you are spending less time fetching operands you need fewer cycles | 18:58 |
| ikskuh | lofty: cycles aren't my problem | 18:59 |
| lofty | And thus your CPU executes the same instruction stream faster | 18:59 |
| *** indy <[email protected]> has quit IRC (Quit: ZNC 1.8.2 - https://znc.in) | 18:59 | |
| Sarayan | but in any case if your cpi goes from 4 to 1.mumble even if your cycle gets slower it doesn't amtter | 18:59 |
| Sarayan | (4 = read instruction, read two values, write one) | 19:00 |
| lofty | "cycles aren't my problem" <-- then why come to us for help speeding up your CPU if it doesn't matter? | 19:00 |
| ikskuh | i don't want "less cycles", but "faster cycles" | 19:00 |
| ikskuh | i want to have a clk of 160 MHz | 19:00 |
| lofty | That's why you have the pipeline! | 19:00 |
| ikskuh | due to other parts in the design | 19:00 |
| ikskuh | and a central memory bu | 19:00 |
| ikskuh | *bus | 19:01 |
| Sarayan | ok | 19:01 |
| ikskuh | so if my cpu access this bus, it needs to react in 1 clk | 19:01 |
| Sarayan | how are your instructions encoded? | 19:01 |
| ikskuh | 1 u16 for "all information", then up to two immediates or stack operations as input0 and input1 | 19:01 |
| lofty | You are talking to us about how the number of decisions causes your CPU to be slow, right? | 19:01 |
| lofty | You are trying to decide everything at once per cycle | 19:02 |
| lofty | The solution is therefore to not decide everything at once | 19:02 |
| Sarayan | so you have 4 cycles per instruction pretty much always? | 19:02 |
| ikskuh | Sarayan: kinda, yeah. except for memory ops (ld8, ld16, st8, st16) and mul/div/mod | 19:03 |
| ikskuh | instruction encoding: https://ashet.computer/specs/spu-mark-ii/#instruction-encoding | 19:03 |
| tpb | Title: SPU Mark II - Ashet Home Computer (at ashet.computer) | 19:03 |
| lofty | You don't need a mod instruction, but anyway | 19:03 |
| ikskuh | lofty: so one solution would be to have "more, but dumber steps" in the state machine? | 19:04 |
| lofty | Having more steps means more decisions | 19:04 |
| lofty | And having fewer steps means more decisions done per cycle | 19:04 |
| Sarayan | well, the #1 question is do you have prefetching? | 19:04 |
| ikskuh | no | 19:04 |
| lofty | fundamentally, you cannot resolve your problem within the framework of a finite state machine | 19:04 |
| lofty | and so you must leave it. | 19:05 |
| ikskuh | lofty: i got that part, but i don't understand HOW to leave | 19:05 |
| ikskuh | this is something i've never done | 19:05 |
| lofty | Can you draw a graph of the steps of your state machine | 19:05 |
| ikskuh | i'll try | 19:05 |
| lofty | the goal is that a chain of steps within your state machine becomes a pipeline | 19:06 |
| Sarayan | if you don't have prefetching you have an extremely hot path where in the cycle the memory must return the instruction read result, you must decode the instruction and push the next address on the bus | 19:06 |
| Sarayan | that's a lot of computation which starts with waiting for the memory to answer | 19:07 |
| Sarayan | you really need to separate fetch from decode | 19:07 |
| lofty | Here's the teaching example I normally go for: washing batches of laundry. You have a washing machine and a tumble dryer. | 19:08 |
| lofty | What you are doing here is taking the time to get a batch of laundry, then standing around waiting for it to wash, then standing around waiting for it to dry, then hanging it up | 19:08 |
| lofty | whereas you could be simultaneously getting the laundry while one batch washes and another batch dries | 19:09 |
| lofty | That is, fundamentally, a pipeline | 19:09 |
| lofty | Where you have a state machine that has the state for steps A, B, C, D and executes them in the order A -> B -> C -> D, then what Yosys will do is execute A, B, C, and D simultaneously and then decide the result | 19:10 |
| lofty | Which is slower than doing A, B, C, and D simultaneously and unconditionally | 19:11 |
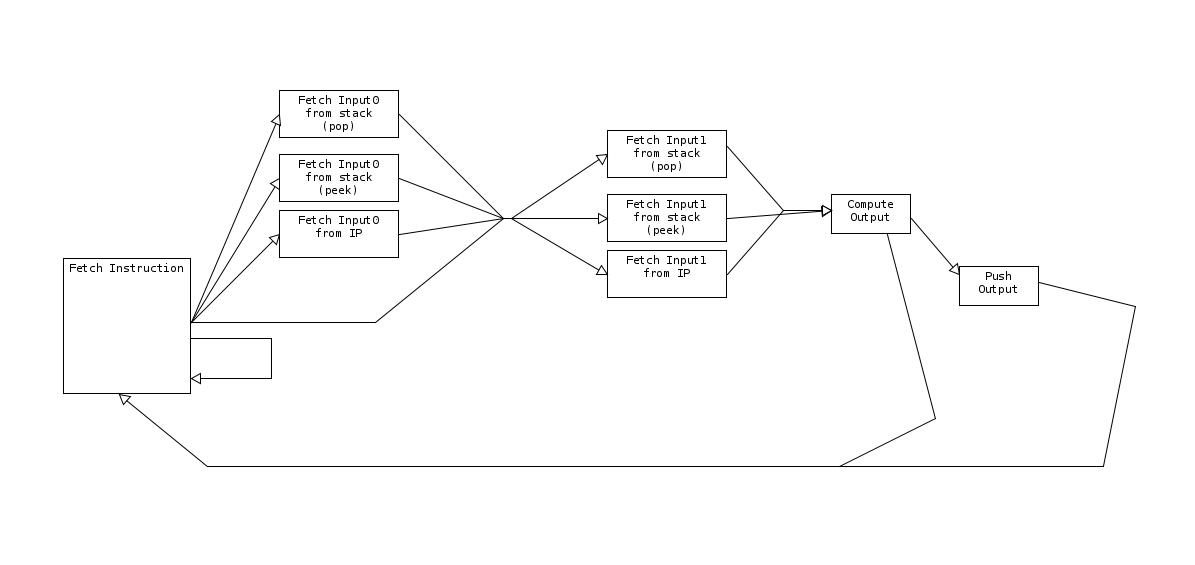
| ikskuh | https://mq32.de/public/e78287e99aa734c4db3c791095273fe7532dd8fc.png | 19:11 |
| ikskuh | state machine | 19:11 |
| lofty | I'm rambling, sorry. | 19:11 |
| Sarayan | otoh, pipelines are rather hard with stack machines | 19:11 |
| Sarayan | but prefetching isn't, and it's going to help a lot | 19:12 |
| lofty | Sarayan: this state machine looks very pipeline-y to me | 19:12 |
| ikskuh | lofty: but each part of the pipeline will only activate every nth cycle, right? | 19:12 |
| lofty | For your case, yes | 19:13 |
| Sarayan | something easy to try, instead of executing the instructions in the order "read instruction, read param1, read param2, write result" try "read param1, read param2, read next instruction, write result", with an initial read instruction at reset and on jumps of course | 19:13 |
| Sarayan | if you manage it your hot path should be way less hot | 19:13 |
| Sarayan | because 1/ you can compute the result to be written while you're reading the next instruction | 19:14 |
| ikskuh | Sarayan: problem is: i left interrupt handling out /o\ | 19:14 |
| ikskuh | but let's ignore that for now | 19:14 |
| Sarayan | 2/ you can decode the instruction while writing the result | 19:14 |
| Sarayan | these are two hot paths fetch to decode and compute to write | 19:15 |
| Sarayan | that way you split them over two cycles | 19:15 |
| ikskuh | what does "decoding" mean exactly? | 19:15 |
| ikskuh | the instruction is just a bunch of bit fields | 19:16 |
| ikskuh | determining what each part of the "pipeline" does | 19:16 |
| Sarayan | decoding for instance is computing where to read param1 | 19:16 |
| ikskuh | ah, so "look at the instruction word" | 19:17 |
| Sarayan | you have the whole "write result" cycle to compute that address rather than having to do it immediatly | 19:17 |
| ikskuh | let me think about that | 19:18 |
| ikskuh | and if i don't have "write result", i just stall then? | 19:18 |
| Sarayan | yeah | 19:19 |
| *** Max-P <Max-P!Max-P@thelounge/maintainer/Max-P> has joined #yosys | 19:19 | |
| ikskuh | hm | 19:19 |
| ikskuh | but only for one clk, right? | 19:19 |
| Sarayan | yep | 19:19 |
| ikskuh | and if i actually have to do memory access, i'll "stall" for "how long that memory access takes" | 19:20 |
| Sarayan | you memory is slower than 160MHz? | 19:20 |
| ikskuh | yes, i have an external 16 MB SPI flash and 16 MB SDRAM | 19:20 |
| Sarayan | ouch, you really really really want some kind of cache for instructions and stack :-) | 19:21 |
| ikskuh | yes, i know | 19:21 |
| ikskuh | but those are secondary problems | 19:22 |
| ikskuh | i wanna do everything step by step | 19:22 |
| Sarayan | try prefetching, it should have an interesting impact | 19:22 |
| ikskuh | and my current design allows me to tack caches for dram, flash, ... :) | 19:22 |
| ikskuh | yeah, i think i got the rough idea now | 19:22 |
| ikskuh | this will take a while to get right | 19:22 |
| ikskuh | but one very good thing: i already have a behaviour test suite | 19:23 |
| ikskuh | so i can see if i break things on the way | 19:23 |
| Sarayan | that's useful | 19:23 |
| ikskuh | or if everything still works as intended | 19:23 |
| ikskuh | but i think i will try prefetching and "pipelining" | 19:24 |
| ikskuh | also separate instruction and data bus for separate caches | 19:24 |
| Sarayan | pipelining is hard to get right with a stack architecture | 19:24 |
| ikskuh | yeah, but the general idea of "not doing a state machine" | 19:24 |
| Sarayan | honestly it's all a state machine in the end | 19:25 |
| ikskuh | right | 19:25 |
| ikskuh | but trying to do more in parallel | 19:25 |
| ikskuh | and not cramping everything into a single process | 19:25 |
| Sarayan | yes, that's the important part | 19:25 |
| ikskuh | this will take a day to see what i can all do in parallel | 19:25 |
| Sarayan | not having long chains of dependencies in the same clock | 19:25 |
| ikskuh | but the idea of running "add" in parallel to "sub" and "shift" is the right idea, yeah? | 19:26 |
| Sarayan | if you have to data to run them with in parallel | 19:27 |
| ikskuh | alu only has two inputs "input0" and "input1" | 19:27 |
| ikskuh | and will output a single value which you can inspect for flags and/or push | 19:27 |
| ikskuh | so i have one step "add input0, input1, store output", one "select the output from the alu", one "push the output" parallel to "set the flags", right? and while i compute the output of the alu, i can fetch and decode the next instruction | 19:29 |
| ikskuh | did i get this right? | 19:34 |
| Sarayan | you fetch it while you compute the output of the alu, you decode it while you write the output of the alu | 19:35 |
| Sarayan | you don't want to do fetch and decode in the same cycle, it's too much | 19:36 |
| ikskuh | okay | 19:38 |
| ikskuh | so "way more registers" :D | 19:38 |
| Sarayan | of course | 19:42 |
| *** tlwoerner <[email protected]> has quit IRC (Remote host closed the connection) | 20:03 | |
| *** tlwoerner <[email protected]> has joined #yosys | 20:04 | |
| *** FabM <FabM!~FabM@armadeus/team/FabM> has quit IRC (Ping timeout: 268 seconds) | 20:07 | |
| *** ec <ec!~ec@gateway/tor-sasl/ec> has quit IRC (Remote host closed the connection) | 20:10 | |
| *** ec <ec!~ec@gateway/tor-sasl/ec> has joined #yosys | 20:11 | |
| *** ec <ec!~ec@gateway/tor-sasl/ec> has quit IRC (Ping timeout: 276 seconds) | 22:52 | |
Generated by irclog2html.py 2.17.2 by Marius Gedminas - find it at https://mg.pov.lt/irclog2html/!
{kind=link}